Managed RPC vs Self-Hosted Solana RPC: A Decision Framework for Production Teams
Compare managed, dedicated, self-hosted, and hybrid Solana RPC models by cost, operations, performance, data access, security, and workload fit.

Managed vs self-hosted RPC becomes a real decision once Solana traffic moves beyond free public endpoints and starts depending on predictable reads, streams, and transaction submission. How a specific ownership model aligns with the workload, the team's operational capacity, and the application's risk profile matters more than surface preferences about hosting style.
The practical trade-offs across shared managed, dedicated managed, self-hosted, and hybrid models are covered in the Solana RPC infrastructure guide. If the question is whether free Solana RPC endpoints are sufficient at all, that is an earlier decision and a separate one.
Managed RPC vs self-hosted Solana RPC: what decision are you actually making?
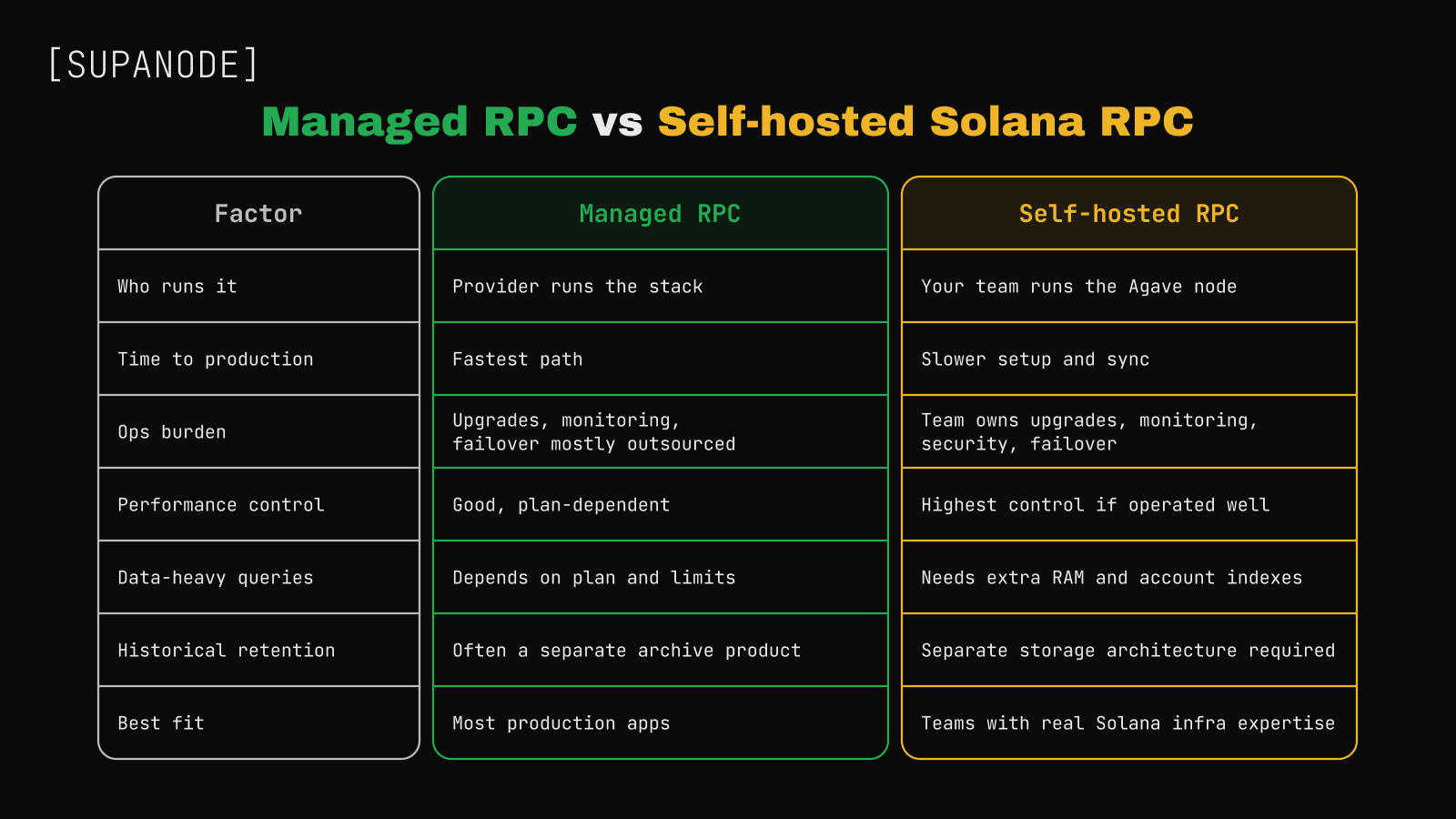
This is a control-allocation decision.
Opting for a managed provider effectively outsources the bulk of the node lifecycle — from provisioning and health checks to routing, upgrades, redundancy, and endpoint controls — while a self-hosted setup transforms RPC into an internal service that demands continuous design, observation, and maintenance. That second framing is the part teams often price too lightly.
Solana's own documentation reflects this. Public endpoints are shared infrastructure, explicitly not intended for production applications. Agave's RPC node setup explains that an RPC server runs the same process as a consensus validator and should not be exposed to the public internet without proper abuse protection. The decision is less about server ownership and more about who owns the operating risk.
The comparison is frequently distorted by the twin assumptions that self-hosting is inherently more cost-effective and that managed RPC operates merely as a rebranded public endpoint. The real comparison is between shared managed, dedicated managed, self-hosted, and hybrid models — and those four things are meaningfully different products that attract different teams for different reasons.
As a rule of thumb, teams whose competitive advantage lies entirely within the application layer tend to default to managed infrastructure, whereas those treating engineering control as their primary edge find the overhead of self-hosting easier to justify.
What managed Solana RPC means in production
Managed RPC means a provider operates the infrastructure and the team consumes endpoints — HTTP, WebSocket, sometimes gRPC — without running the node stack internally.
"Managed" covers a wide range. At the low end, it can mean a shared multitenant endpoint with rate limits and no guarantees. At the high end, it means dedicated infrastructure with custom configuration, SLAs, isolated node pools, and support that can diagnose Solana node behavior under incident conditions. Dedicated managed RPC is a meaningfully different product from shared managed RPC, and conflating them leads to the wrong comparison.
What a well-built managed provider typically absorbs:
- Node provisioning, sync, and ongoing health
- Agave version tracking and upgrades
- Redundancy and failover (plan-dependent)
- Endpoint authentication and access controls
- Abuse protection and rate limiting
- Monitoring and alerting at the infrastructure layer
The degree to which those things are included varies by provider and by plan tier. In practice, managed RPC shifts much of the operational surface away from the application team.
For WebSocket subscriptions and gRPC streaming, the picture is slightly different. JSON-RPC and WebSocket are native Agave surfaces that come with a standard node. gRPC — via Yellowstone/Geyser — is a separate plugin-based path, not a default feature of the base RPC service. Managed providers increasingly offer this as a separate product layer. Whether it is bundled or priced separately is worth confirming before assuming it is included.
What self-hosted Solana RPC actually requires
Self-hosting is often reduced to "spin up a server and point the app at it." That framing misses most of the operational surface.
A self-hosted Solana RPC node is a stateful infrastructure service. The official Agave node documentation is explicit: an RPC node runs the same core process as a consensus validator. Operators typically run it in non-voting mode with --full-rpc-api and --private-rpc flags. Non-voting does not mean lightweight — the operational burden is comparable, and often heavier depending on the method mix.
The team owns all of this:
- Hardware sizing and procurement
- Initial sync and snapshot bootstrapping
- Disk management: separate NVMe volumes for Accounts, Ledger, and Snapshots
- Ongoing slot freshness and health monitoring
- Agave version tracking, staged upgrades, and rollback capacity
- Endpoint exposure, authentication, and rate limiting
- WebSocket keepalives and connection management
- Failover and backup node logistics
- Incident response when things degrade
The Agave RPC node documentation also notes that running one node as both a consensus validator and a full RPC node is generally not practical due to resource constraints. Teams already running a validator should not assume the RPC workload can share it cleanly.
Self-hosting only works when ownership is explicit: slot-lag alerts, upgrade rollbacks, disk pressure, endpoint abuse, and incident response all need named owners.
Cost is not just the server
The server is the most visible line item. It is rarely the largest.
Official node-operator guidance sets a hardware floor that already implies significant cost: a high-clock modern CPU, 16+ cores / 32+ threads for RPC-specific workloads, ECC RAM at 256 GB or more (higher when running account indexes), and multiple high-TBW NVMe drives. Accounts, Ledger, Snapshots, and the OS should live on separate physical devices — putting Accounts and Ledger on the same disk is explicitly warned against.
Once indexes for heavy methods like getProgramAccounts are added, memory requirements increase substantially. Treating memory as the only scaling lever will not cover it — the storage layout, TBW budget, and network capacity all shift as well.
| Cost category | Managed RPC | Self-hosted RPC | What the team should ask |
|---|---|---|---|
| Core compute | Bundled into plan | Bare metal or cloud you own | Is our workload bursty, regional, or predictable? |
| RAM and indexes | Abstracted by plan features | Direct team cost, especially for indexed heavy methods | Do we rely on getProgramAccounts or token-owner/mint reads at scale? |
| NVMe and storage endurance | Hidden behind service | Direct responsibility, including TBW and disk isolation | Are accounts, ledger, snapshots, and OS correctly separated? |
| Network and bandwidth | Bundled or quota-based | Directly billed | How much bandwidth do streams and historical syncs consume? |
| Redundancy and failover | Often built into dedicated or enterprise tiers | Requires additional node(s), load balancer, failover logic | Who owns HA, and is it needed everywhere or only on critical paths? |
| Security controls | Usually includes auth, rate limits, token/JWT, DDoS mitigation | Designed and operated internally | Can the endpoint be safely exposed at all? |
| Monitoring and on-call | Largely provider-side | Team-owned | Who gets paged for slot lag, WebSocket drops, or landing regressions? |
| Upgrades and release tracking | Provider-managed | Team-managed | Can we stage, validate, and roll back Agave upgrades safely? |
| Historical data | Separate archive/stream products | Requires separate retention design or external storage | Do we need hot reads, cold history, or both? |
| Engineering opportunity cost | Lower infrastructure overhead | Higher infrastructure drag | Is infra a differentiator or a distraction? |
A TCO model that excludes redundancy, endpoint protection, upgrade cycles, and historical data strategy is not a Solana RPC TCO model. It is a server quote.
Performance: self-hosted does not automatically mean faster
Self-hosted RPC does not automatically mean lower latency.
"Faster" needs to be decomposed. HTTP RPC response time, WebSocket notification delay, gRPC stream freshness, and transaction landing are distinct performance surfaces. Improving one does not guarantee improvement on the others.
A successful RPC response indicates only that the node accepted the transaction for relay, leaving cluster processing and ultimate confirmation to network-level dynamics — blockhash expiry, priority fee calibration, submission path behavior — none of which the RPC acknowledgment itself controls. That is why transaction landing needs separate tracking: fresh blockhashes, confirmation checks, priority fee estimates, and retry behavior cannot be inferred from HTTP read latency.
A node colocated with the application in the right region may reduce HTTP p50. But if the actual bottleneck is WebSocket freshness, what matters is the quality of the subscription path and keepalive handling. If the bottleneck is transaction landing, blockhash freshness, retry strategy, priority fee logic, and leader-path connectivity matter more than read response times.
A poorly maintained self-hosted node — lagging in slots, storage-constrained, or overexposed — can underperform a well-tuned dedicated managed endpoint. Self-hosting only wins on performance when the team can keep the node fresh, isolated, monitored, regionally aligned, and tuned for the actual method mix.
The low-latency Solana RPC benchmark methodology goes deeper on measurement approach. The dimensions worth testing:
- p50 / p95 / p99 response time per method
- Error rate and timeout rate under realistic concurrency
- Slot lag over time
- WebSocket event delay under subscription load
- gRPC event delay if streaming is part of the workload
- Transaction submission and confirmation tracking
- Method mix and region
- Test duration long enough to capture slot lag drift
A rapid getBalance loop is not enough to benchmark complex production workloads.
Data access, account indexes, and historical queries
This is where the RPC architecture decision matters most.
Heavy use of getProgramAccounts and token-account queries by owner or mint requires account indexes to avoid poor performance at scale. The Agave RPC node documentation recommends --account-index flags for program-id, spl-token-mint, and spl-token-owner. Building and maintaining those indexes has a real memory cost — it is one of the reasons workloads dependent on these methods need to be sized differently from general-purpose RPC nodes.
Once the workload depends on heavy indexed reads, the team is sizing an indexed data service, not just an RPC node. The hardware requirements and operational model shift accordingly.
Historical data adds another layer. Anza's docs note it is not practical for an RPC node to store the entire blockchain locally. Teams with longer retention needs require external storage infrastructure alongside the RPC node. On-node history accumulates at a meaningful daily rate, and beyond a few days of retention the storage planning becomes a separate architectural decision.
The practical point: RPC, indexer, gRPC stream, and historical archive are different products. Forcing all of them through one node usually creates avoidable constraints — and that holds regardless of whether the node is managed or self-hosted.
For teams whose workload relies heavily on Solana RPC API methods like getProgramAccounts, the distinction between RPC, indexer, and historical data is often the more consequential architectural question.
WebSocket, gRPC, and stream-heavy workloads
WebSocket delay is not the same as HTTP RPC latency. For DeFi dashboards, analytics pipelines, wallet updates, and trading bots and execution infrastructure, the stream path, rather than standard read response time, typically emerges as the primary operational bottleneck.
gRPC via Yellowstone/Geyser is a separate path from the base Agave RPC service. It requires a Geyser plugin, separate configuration, and explicit operational attention. Managed Yellowstone/Geyser streaming products expose filtered delivery across accounts, transactions, slots, blocks, and block metadata as a purpose-built layer. Treating gRPC as a simple toggle on an existing RPC node creates the wrong expectation about what is involved.
For self-hosted teams, adding Yellowstone/gRPC means owning the plugin path, keepalive behavior, connection handling, and delivery reliability on top of everything else the node already requires. For teams without dedicated infrastructure staff, managed gRPC is often more practical to operate sustainably.
The architecture question for stream-heavy workloads is not just managed vs self-hosted — it is also whether the read path, stream path, and write path should share the same infrastructure at all.
Transaction landing and write-heavy workloads
A sendTransaction response confirms the node accepted the transaction for relay. Whether it lands depends on blockhash freshness, priority fee strategy, retry logic, leader connectivity, and network conditions at submission time.
Self-hosted RPC alone does not fix a weak transaction-sending strategy. A team that has optimized HTTP p50 but has not addressed blockhash refresh intervals, fee estimation, and retry behavior will still see landing failures. Dedicated or managed infrastructure with a tuned submission path can help — but the impact depends on the specific workload and needs to be benchmarked.
If transaction landing is a core performance requirement, it warrants its own evaluation, separate from the general RPC architecture decision.
Security and endpoint exposure
The Agave RPC node setup documentation is direct: the RPC service is not intended to be exposed to the public internet without real abuse protection in place.
The moment a self-hosted node becomes a production dependency, the team owns:
- Authentication (API keys, JWT, IP allowlists)
- Method-level access controls and rate limits
- Abuse detection and mitigation
- Request logging and anomaly monitoring
- Endpoint rotation when credentials change
- WebSocket connection abuse protection
Managed providers absorb parts of this surface. Features like token-based authentication, header-based auth, referrer allowlisting, method-level rate limits, and DDoS mitigation are common components of mature managed RPC platforms. The specifics vary by provider and plan.
For teams running self-hosted infrastructure, RPC endpoint security controls covers the specific measures worth implementing. Self-hosted gives full control, but every gap in the security model is the team's responsibility to find and close.
When managed RPC is the better choice
Managed RPC is usually the better starting point when:
- The team needs to reach production without building out infrastructure capacity first
- There is no dedicated Solana infra engineer on the team
- The workload is standard production load — mixed reads, WebSocket subscriptions, transaction submission — without requirements that justify custom infrastructure
- Predictable operations matter more than direct control
- The team wants endpoint isolation, WebSocket/gRPC access, or custom rate limits without running the stack internally
- Benchmarking is still in progress and the team wants a reliable baseline before committing to a longer-term architecture
Managed does not mean cheaper in all cases. At high traffic volumes, a dedicated managed node can cost more than comparable bare metal. Once engineering time, monitoring, upgrades, redundancy, and incident response are included honestly in the TCO, managed infrastructure often becomes more cost-competitive than the hardware price alone suggests.
When self-hosted Solana RPC makes sense
Self-hosted is the better fit when:
- The team has real Solana node operations experience — slot lag, snapshots, Agave upgrades, and disk pressure are known problems with known owners
- Infrastructure is part of the product's competitive edge (custom indexing, private routing, specific colocation requirements)
- Traffic volume and workload stability make owning the stack economically justified over time
- Strict network isolation, compliance requirements, or private networking constraints apply
- The workload requires custom indexes or data pipelines that standard RPC endpoints cannot serve
- Direct control over the gRPC stream path or transaction routing is part of the performance strategy
- The team can fully own monitoring, upgrade cycles, failover, and incident response
Self-hosted infrastructure should not be treated as an automatic path to lower latency, lower cost, or simpler operations. Control only helps if the team can operate the system during incidents.
The hybrid model
The most realistic end-state for a mature Solana team is often neither fully managed nor fully self-hosted.
A hybrid architecture typically looks like this: managed or dedicated managed RPC handling broad production traffic, a self-hosted node serving narrow internal reads or a specific private transaction path, gRPC streaming handled through a separate layer, and historical data offloaded to purpose-built archive infrastructure. Read and write paths may be deliberately separated.
A hybrid setup follows naturally from treating RPC, gRPC streams, indexed queries, and historical data as distinct products with different operational requirements — separating them into isolated tracks rather than forcing everything through one node. Pushing everything through one node tends to create constraints at scale that are harder to untangle later than they look upfront.
From an HA perspective: a single self-hosted node is a single point of failure. Once high availability becomes a requirement, the team is building a fleet — multiple stateful nodes, a load balancer, health-based routing, and failover logic. A hybrid approach often lets teams apply that investment narrowly, where it creates real product advantage, while managed infrastructure handles the rest.
Decision matrix
| Decision factor | Shared managed RPC | Dedicated managed RPC | Self-hosted RPC | Hybrid model |
|---|---|---|---|---|
| Time to production | Fastest | Fast | Slower | Moderate |
| Control over config and routing | Limited | Medium to high | Highest | High where it matters |
| Operational burden | Lowest | Lower than self-hosted | Highest | High but targeted |
| Cost predictability | High | High | Variable (hardware + engineering) | Mixed |
| Latency consistency | Depends on shared load | Usually stronger than shared | Depends on engineering quality | Potentially strongest if paths are split |
| WebSocket / gRPC needs | Often available, plan-dependent | Stronger fit | Requires explicit Yellowstone operation | Best when stream and read paths are separated |
| Account indexes / heavy methods | Often rate-limited | Better fit | Strong if RAM/index cost is covered | Strongest when isolated to private nodes |
| Historical data | Product-dependent | Product-dependent | Separate architecture problem | Best handled out-of-band |
| Failover | Often built into higher tiers | Built into plan | Requires duplicate node + load balancer | Managed layer provides failover |
| Security burden | Mostly provider-side | Shared | Team-side entirely | Shared and selective |
| Team requirements | None specific | Minimal Solana knowledge helpful | Dedicated Solana infra expertise required | Mixed |
| Best fit | Teams optimizing for speed and simplicity | Production teams needing isolation without full self-operation | Teams whose edge is infra control | Mature teams with mixed or complex workloads |
Workload-based recommendation
| Workload | Recommended starting model | Why |
|---|---|---|
| Prototype or test app | Managed shared | Fastest path, no infra overhead at early stage |
| Early production dApp | Managed shared or small dedicated | Manageable ops overhead, room to grow |
| Wallet or frontend-heavy app | Managed or dedicated managed | Broad read mix, subscriptions, predictable support surface |
| DeFi dashboard | Dedicated managed or hybrid | Stream freshness matters more than generic read latency |
| Trading bot or latency-sensitive execution | Dedicated managed or hybrid; self-hosted only for narrow paths | Write path, stream path, and read path are different problems |
| Analytics or indexing platform | Hybrid or self-hosted with separate archive layer | RPC alone is not the data platform |
| High-volume app with infra team | Dedicated managed first, then hybrid where justified | Own only what creates advantage |
| Compliance or private networking | Self-hosted or tightly customized dedicated managed | Network control requirements dominate the decision |
How to choose
Before committing to an architecture, work through this sequence:
- Map the method mix. What percentage of calls are reads vs writes vs subscriptions? Are any of them
getProgramAccounts-heavy or token-index-heavy? - Estimate traffic and concurrency. What does sustained load look like, and what does peak look like — and are those numbers measured or guessed?
- Define freshness and latency requirements. HTTP p50 target, WebSocket delay tolerance, gRPC event delivery requirements.
- Clarify historical data needs. On-chain history beyond a few days is a separate architecture decision, not an RPC node configuration.
- Calculate honest TCO. Include hardware, bandwidth, redundancy, monitoring, endpoint security, upgrade time, and engineering on-call. Missing lines make the model incomplete.
- Decide who owns incident response. Slot lag, WebSocket disconnects, disk pressure, transaction landing regressions — these need named owners before the node is production.
- Benchmark before committing. Test the actual method mix under realistic concurrency. Cover p50/p95/p99, error rate, timeout rate, slot lag, and stream delay.
The architecture decision becomes easier once the workload is measured.
Benchmark the workload first. Supanode can help size managed, dedicated, or hybrid Solana RPC infrastructure and, where relevant, run a 48-hour trial before the team commits to a long-term setup. View RPC pricing →







