Solana Trading Bot Guide: Types, Risks, and Infrastructure
Learn how Solana trading bots work, what types of bots exist, and why RPC latency, real-time data, priority fees, retries, and failover matter in production.

A Solana trading bot is an automated system that reads on-chain or market data, applies some predefined logic, and submits transactions to Solana. That is the short answer, and it is accurate enough to start. But the moment a Solana bot becomes anything more than a prototype — when latency, capital, or other people's money is involved — the real question stops being "which bot should we use?" and becomes "why do our transactions keep missing, expiring, or failing at the worst possible moment?"
That shift is what this guide is about. We will start with the basics — what a Solana trading bot is, what types exist, how Telegram bots differ from GitHub scripts and custom backends — and then work through the production infrastructure that separates something that mostly works from something that reliably lands.
What is a Solana trading bot?
A Solana trading bot is software that monitors signals — a DEX quote, a new pool listing, an order book change, a wallet event, a scheduled rebalance — decides whether to trade based on some logic, and turns that decision into a signed transaction sent to the Solana network.
Simple bots may run through a Telegram UI or a SaaS dashboard, where the infrastructure is mostly hidden from the user. There are also free Solana trading bot options on GitHub — scripts you can clone and run — and SaaS products with dashboards, and Telegram bots that let you trade from a chat window. The delivery mechanism changes depending on which route you take, but every path still ends at the same place: a signed transaction that needs to land on-chain before the blockhash expires.
More complex setups involve custom backends that sit behind a prop strategy, a DeFi product, or a market-making engine. Whether it is a sniper bot crypto workflow or a portfolio rebalancing tool, the underlying mechanics are the same: read data, decide, build a transaction, set fees, submit, track what happened.
One thing worth stating clearly: a Solana trading bot is an automation layer. The quality of what it produces depends on strategy logic, yes, but also on data freshness, routing, fee calibration, how it submits transactions, and what it does when something goes wrong. Solana's own RPC documentation makes that dependency explicit — sendTransaction means the node accepted a signed payload, not that the cluster confirmed it. A transaction can still be dropped or expired before landing.
Common types of Solana trading bots
Most Solana bot workloads fall into a handful of categories, and the category matters because it determines how latency-sensitive the system is and what kind of infrastructure it needs.
Solana arbitrage bot. Watches price discrepancies across venues — DEXes, CLMMs, CLOBs — and tries to capture the spread before it closes. Latency here is not just about network ping. It includes data freshness, quote age, build time, and how quickly the transaction actually lands.
Solana listing bot. Monitors for new pools or newly tradable assets and submits time-sensitive transactions when they appear. Sometimes called a sniper bot crypto workflow. The window is often very short, which means every millisecond of infrastructure slack matters. If you are specifically researching this use case, the Solana sniper bot guide goes deeper on what the execution stack looks like.
Copy trading bot. Mirrors another wallet or strategy in near real time. The challenge is usually data freshness — detecting the source transaction quickly enough that copying it still makes sense.
Market-making bot. Posts and replaces quotes continuously. Quote staleness, fee efficiency, and cancel-replace latency all drive outcomes.
Portfolio or rebalancing bot. Executes on a schedule or trigger rather than in a latency race. The infrastructure bar is lower, but fee logic and confirmation tracking still matter — especially when markets are moving.
Alert-driven or semi-automated bot. Automates data collection and pre-trade plumbing but leaves the final decision to a human. Lower stakes on execution speed, but stream reliability and data freshness still affect usefulness.
Telegram bot, SaaS bot, GitHub bot, or custom Solana bot?
The most common question at the start is which type of bot to use. An honest comparison:
| Type | Best for | Main limitation |
|---|---|---|
| Telegram bot | Retail users, quick setup | Some setups require wallet import or exposed signing keys — custody risk |
| SaaS bot | Non-technical users | Vendor lock-in, limited visibility into routing and fee logic |
| GitHub bot | Developers learning or prototyping | Maintenance burden, security risks, often outdated defaults |
| Custom bot | Teams with strategy and engineering capacity | Requires full infrastructure ownership across every layer |
| Production bot stack | Trading products and high-volume workloads | Requires dedicated RPC, real-time data, monitoring, retries, failover |
A few things worth adding to that table. Searching for a Solana trading bot Telegram option is how a lot of people start — the setup is fast and the UI is familiar, but some Telegram bot setups require users to import wallets or expose signing keys, which creates custody risk that is easy to underestimate when the interface looks simple. Searching for a free Solana trading bot usually leads to GitHub repos, which are fine for learning and prototyping, but public repos sometimes contain hardcoded keys, abandoned retry logic, and fee strategies that were already outdated when someone pushed them two years ago. A Solana trading bot GitHub search can turn up genuinely useful open-source tooling, but it requires more skepticism than most tutorials suggest.
Custom and production stacks give full control, but they also mean owning everything: RPC selection, data streams, fee calibration, transaction building, retry loops, failover, and post-trade tracking. Most teams find that list longer than it looked from the outside.
Benefits of using a Solana trading bot
The honest case for automation on Solana is not about guaranteed returns. It is about execution consistency at a speed that manual workflows cannot match.
- Bots react to on-chain events faster than any manual workflow
- Strategy logic runs consistently, without emotional drift or missed signals
- A single system can monitor many pools, markets, or accounts simultaneously
- Routing and fee logic wire directly to APIs rather than getting estimated by hand
- Repetitive execution work — building transactions, estimating fees, tracking confirmations — can be abstracted into reusable components
None of that adds up to a guarantee of profitability — a well-built bot executes whatever strategy it is given, reliably and at speed, which cuts both ways.
Risks and limitations of Solana trading bots
Most bot content online glosses over failure modes, which is exactly why teams keep hitting the same walls.
- Bad strategy is the first risk. Automation executes without judgment. Losses from a flawed strategy happen faster and at higher volume with a bot than without one.
- Slippage and stale data. A quote accurate 300ms ago may not be executable now, especially on active pairs.
- Failed transactions still cost fees. On Solana, fees are charged even when execution fails. A bot that retries blindly burns real lamports on every failed attempt.
- Custody risk from third-party bots. Some Telegram bot setups require users to import wallets or expose signing keys, which creates custody risk that many users underestimate.
- Malicious GitHub repos. Some public Solana bot repos contain intentional backdoors or simply catastrophically bad key management. A free Solana trading bot on GitHub requires more skepticism than most tutorials suggest.
- RPC downtime and rate limits. Solana's public RPC endpoints are documented as shared infrastructure not intended for production — they return
429under rate limits and403when traffic is blocked. A bot without a fallback path fails at exactly the moments it most needs to work. - Poor retry logic. Blind retries with an expired blockhash accomplish nothing and may create duplicate-submission confusion. More common than it should be.
- MEV and account contention. High-value trades attract competition, and account-level contention affects how priority fees need to be calibrated on popular pairs.
Why Solana trading bots are latency-sensitive
Latency in the context of a Solana bot is not just network ping. It is the total time from "signal detected" to "transaction confirmed on-chain," and every step in that pipeline contributes.
The full latency budget includes:
- How fresh the incoming data is — stream lag, block delay, subscription method
- How quickly the strategy engine processes a signal
- How long building and simulating the transaction takes
- How accurately and quickly fees are estimated
- Which path the transaction takes to reach a validator
- Whether the transaction lands before the blockhash expires
- How quickly the system can confirm the result and decide to retry or move on
For a market-making bot operating on a known pool, data freshness of a few hundred milliseconds might be acceptable. For a solana listing bot or sniper bot crypto workflow, any of those steps going wrong means the opportunity is gone.
Solana's blockhash model is the hard constraint here. A recent blockhash is valid for 150 slots — roughly 60-90 seconds under normal conditions, but practically shorter in latency-sensitive windows. sendTransaction returning a signature means the RPC accepted the payload. It does not mean the transaction landed. A bot that cannot distinguish "accepted by RPC" from "confirmed on-chain" is operating partially blind.
For a deeper breakdown of how latency compounds through the execution stack, the Solana sniper bot infrastructure guide goes through this in more detail.
The production infrastructure behind a Solana trading bot
Once a Solana trading bot moves past the prototype phase, it stops being "a bot" in any simple sense. It becomes a workload — a system with multiple components that each have their own failure modes and performance characteristics.
The typical production stack:
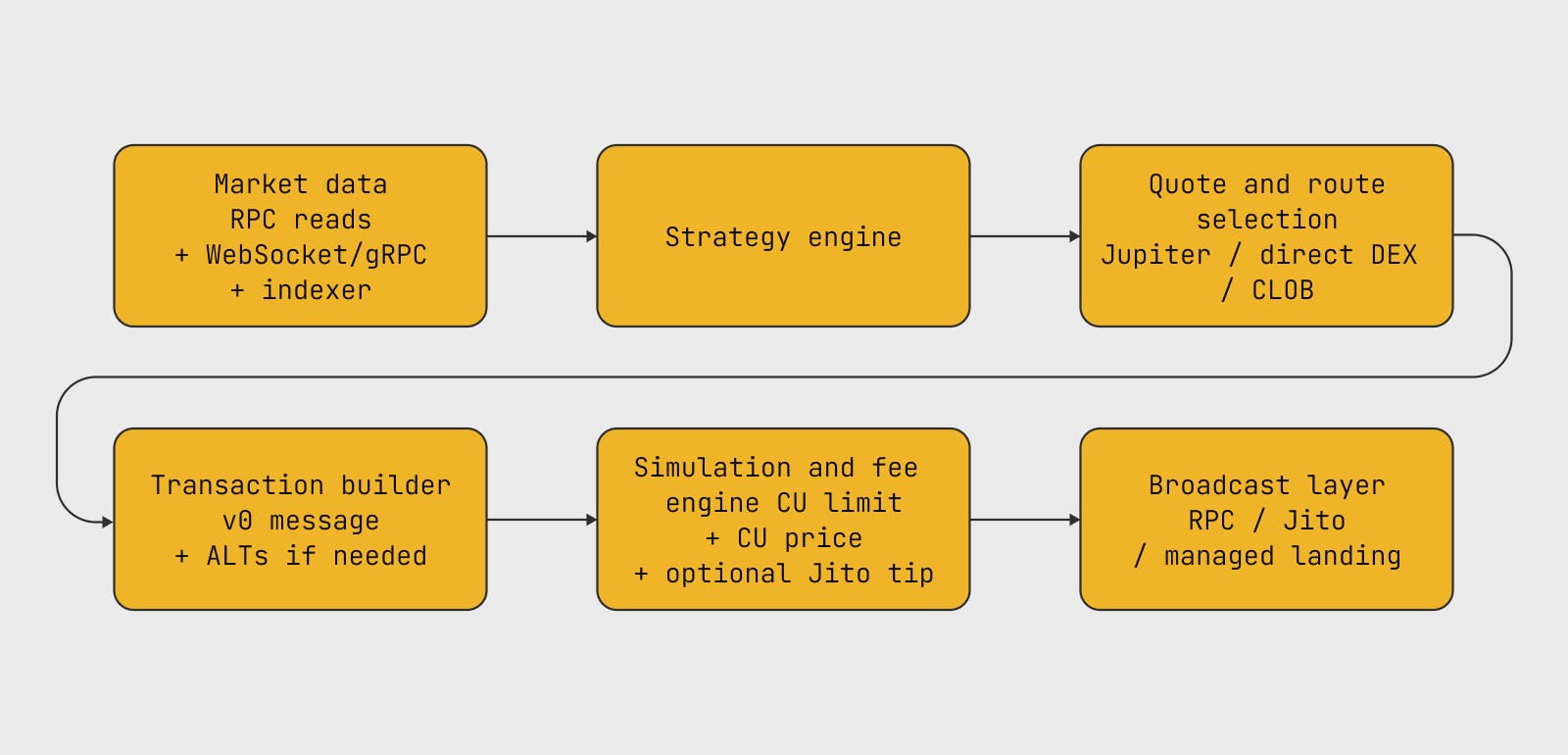
Each step in that chain is a potential failure point. The confirmation tracker is not optional overhead — it is how the system knows whether to retry, re-quote, or move on. Without it, a retry loop can become a duplicate-submission machine.
Separating reads from writes is one of the things that tends to matter more than teams expect early on. The read path needs broad coverage — quotes, program updates, account changes, block events. The write path needs to be narrow, optimized for transaction landing, and easier to reason about under pressure. When both run through the same client and the same endpoint, diagnosing a landing problem becomes much harder than it should be.
RPC endpoints: public, shared, dedicated, and self-hosted
Solana's own documentation says public cluster endpoints are shared infrastructure and are not intended for production applications. That is a first-party statement, not a vendor pitch.
A working breakdown of the options:
- Public RPC — fine for testing and low-stakes exploration. Returns
429under rate limits and403when traffic is blocked. Not suitable for production bot workloads. - Shared RPC — managed provider endpoints on a shared pool. Appropriate for low-volume workloads with predictable patterns. Rate limits apply, and capacity is shared with other tenants during busy periods.
- Dedicated or private RPC — your own node or provisioned capacity. Predictable throughput, configurable limits, no noisy-neighbor effects. Often becomes the right default once consistency, throughput, or transaction reliability start to matter.
- Self-hosted RPC — full control, but full operational burden. Hardware, maintenance, version upgrades, monitoring — all owned internally. Makes sense for teams with requirements that no provider can meet.
Most serious bot teams run a primary dedicated provider and a secondary fallback path. Which providers those are matters less than whether both paths have failover and whether the bot actually knows which one it is using at any given moment.
For a more detailed breakdown of how dedicated and low-latency RPC compares to public endpoints in practice, the low-latency Solana RPC guide covers the architecture decisions.
Real-time data: WebSocket, Yellowstone gRPC, and indexing
The data layer is where bots often lose edges they did not know they had.
WebSocket subscriptions are the baseline — account updates, program logs, slot changes, all accessible via standard WebSocket methods. Reasonable for many workloads, but WebSocket reconnects can create data gaps, and at-processed-commitment latency varies by provider.
Yellowstone gRPC is increasingly the preferred option for backends that need high-throughput, low-latency data. Several providers now offer gRPC as their primary streaming interface for trading workloads, with replay support and more predictable stream behavior than WebSocket connections. Stream recovery behavior matters as much as initial latency — a bot that loses 30 seconds of updates during reconnect is operating on stale state.
Indexing and historical data is the layer that most articles skip. Standard RPC does not support "read this account as of slot N" — validators do not store prior account state for RPC consumption. If strategy evaluation or post-trade analysis requires historical context, the system needs either forward-snapshotting via gRPC or backward reconstruction from transaction history. Without that, you are evaluating the strategy on incomplete information — which is a different problem than having a bad strategy, but produces similar-looking results.
For Solana listing bot use cases and pool monitoring specifically, AMM data monitoring covers how to track new pools and filter relevant signals from background noise.
More detail on WebSocket and gRPC options is in the Solana WebSocket real-time data guide and the Yellowstone gRPC guide.
Routing and swap execution with Jupiter API
Most Solana trading bots that execute swaps use a routing API rather than building every swap instruction from scratch. Jupiter is the dominant aggregator, and its current Swap API V2 exposes two meaningfully different execution paths.
The managed path — /order to get a quote and assembled transaction, /execute to handle landing — is the faster integration. Jupiter handles some of the execution complexity. The trade-off is less control over the transaction structure and submission path.
The self-managed path — /build to get raw instructions and route data — is for teams that need to compose custom transactions, apply their own compute unit limits, or submit through their own RPC or a specific sender. Jupiter's docs recommend simulating the returned instructions to determine the right CU limit rather than using the maximum — over-requesting compute units can multiply priority fees by several times.
For custom bots, the choice between managed and self-managed landing is a real infrastructure decision. If you use /build and then submit through your own RPC, you own the full lifecycle: blockhash freshness, CU estimation, fee policy, retry logic, and confirmation tracking. If you use /execute, some of that is delegated, but you lose some visibility into what actually happened.
More on routing options and how Jupiter's API integrates into a production stack is in the Jupiter API integration guide.
Transaction building: accounts, compute units, and versioned transactions
Every Solana transaction requires a set of accounts, instructions, one or more signatures, and a recent blockhash. That sounds manageable until you start composing multi-step trades, and then the 1,232-byte packet limit becomes real very quickly.
The main lever for complex transactions is versioned transactions with Address Lookup Tables. Solana's v0 format allows accounts stored in an ALT to be referenced using a 1-byte index instead of a 32-byte public key — 31 bytes saved per resolved account. For bots that compose multiple instructions or route through several pools, v0 support is often the difference between a valid packet and a transaction that cannot be built at the required size.
Compute units matter for cost efficiency, not just validity. Solana's fee structure charges based on compute unit price × compute unit limit. The transaction maximum is 1,400,000 CU. If a transaction actually uses 150,000 CU but requests 1,400,000, the priority fee scales with the requested amount — not the consumed amount. Simulation is the right tool for setting CU limits accurately.
Preflight is a related decision. It simulates the transaction at the selected commitment before broadcast, which can catch errors before they cost fees. Some low-latency sender paths disable preflight to reduce submission latency. That trade-off is worth making explicitly, not by default.
Priority fees and transaction landing
The most widely misunderstood part of Solana bot execution is the fee model, and the most important correction is this: sendTransaction returning a signature does not mean the transaction landed
Solana's fee structure separates the transaction cost into a base fee (5,000 lamports per signature) and an optional prioritization fee calculated as compute_unit_price × compute_unit_limit / 1,000,000 lamports. The prioritization fee is how a transaction signals to validators that it should be included ahead of lower-fee transactions competing for the same block space.
A static fee strategy — hardcoding a fixed priority fee — works acceptably when the network is quiet and competition on hot accounts is low. When market conditions change, account contention spikes, or a specific pool becomes a focus of competing bots, static fees become a tax. The right approach is to pull recent prioritization fee samples from the network via getRecentPrioritizationFees, filter by the specific writable accounts the transaction touches, and set the fee dynamically.
That last point is subtle but important. Priority fee samples filtered by account give a much more accurate signal for competitive transactions than a network-wide median. A swap touching a high-volume pool on a volatile day has very different fee requirements than a rebalance touching a quiet vault.
For a full breakdown of compute units, priority fee mechanics, and cost optimization, the Solana priority fees guide goes through the numbers in detail.
Jito, bundles, and alternative transaction submission paths
Jito is a block engine that offers an alternative submission path for Solana transactions — direct forwarding to validators, bundle atomicity, and a separate auction for block inclusion. It is useful in specific situations. It is not a landing guarantee.
The framing that holds up in practice: Jito provides a different execution path, not a better guarantee. Landing still depends on transaction validity, contention, fee and tip calibration, and network conditions. What Jito adds is a private-ish submission path, the ability to submit atomic bundles of up to five transactions, and a tip-based auction that can improve inclusion odds during competitive windows.
A few specifics worth knowing:
- Bundles execute sequentially and atomically — all succeed or all fail in the same slot
- The minimum tip for bundles is 1,000 lamports, but that minimum is rarely enough during high-demand periods
- Jito tips are separate from Solana priority fees — during competitive conditions, both matter
getBundleStatusesshould be part of any bot that uses bundles, not an afterthought*
One underused feature: if a transaction inside a bundle includes an account key starting with jitodontfront, the block engine rejects any bundle where that transaction is not first — a concrete way to narrow the front-running surface in specific atomic sequences.
Use Jito when the strategy benefits from a private submission path or needs atomic multi-transaction sequences. Fee logic and retry infrastructure still need to be honest regardless of which sender path is active.
Retry logic, blockhash expiry, and confirmation tracking
This is the section most Solana bot articles skip, and it is where real money is lost.
A blockhash is valid for 150 slots — roughly 60 seconds under normal conditions. getLatestBlockhash returns both the blockhash and the lastValidBlockHeight, which should be stored alongside the signature for every transaction the bot submits. That metadata is what makes state-aware retry possible.
The lifecycle of a Solana transaction, classified correctly:
- Built — transaction constructed, recent blockhash attached
- Sent — accepted by the RPC sender (signature returned, no confirmation implied)
- Landed — signature confirmed on-chain at the target commitment
- Failed on-chain — confirmed but execution reverted; fees still charged
- Expired — blockhash validity window passed before the transaction landed
- Dropped — never confirmed, not classifiable as expired by slot; possibly lost in transit
Blind retries — rebroadcasting without checking status — are the source of most duplicate-submission incidents. The right loop checks signature status via getSignatureStatuses, classifies the result, and only rebroadcasts if the transaction is still within its validity window and has not already landed or failed. If the blockhash is expired, rebuilding with a fresh blockhash and usually a fresh quote is the correct path.
Separate RPC errors from on-chain failures in all logging. A 429 from the provider means something different than a reverted instruction, and treating them the same way produces bad signals in monitoring.
Failover architecture for Solana trading bots
Failover in a Solana trading bot is more nuanced than "if primary RPC fails, switch to secondary." The bot needs to know the state of any in-flight transaction before deciding what to do next.
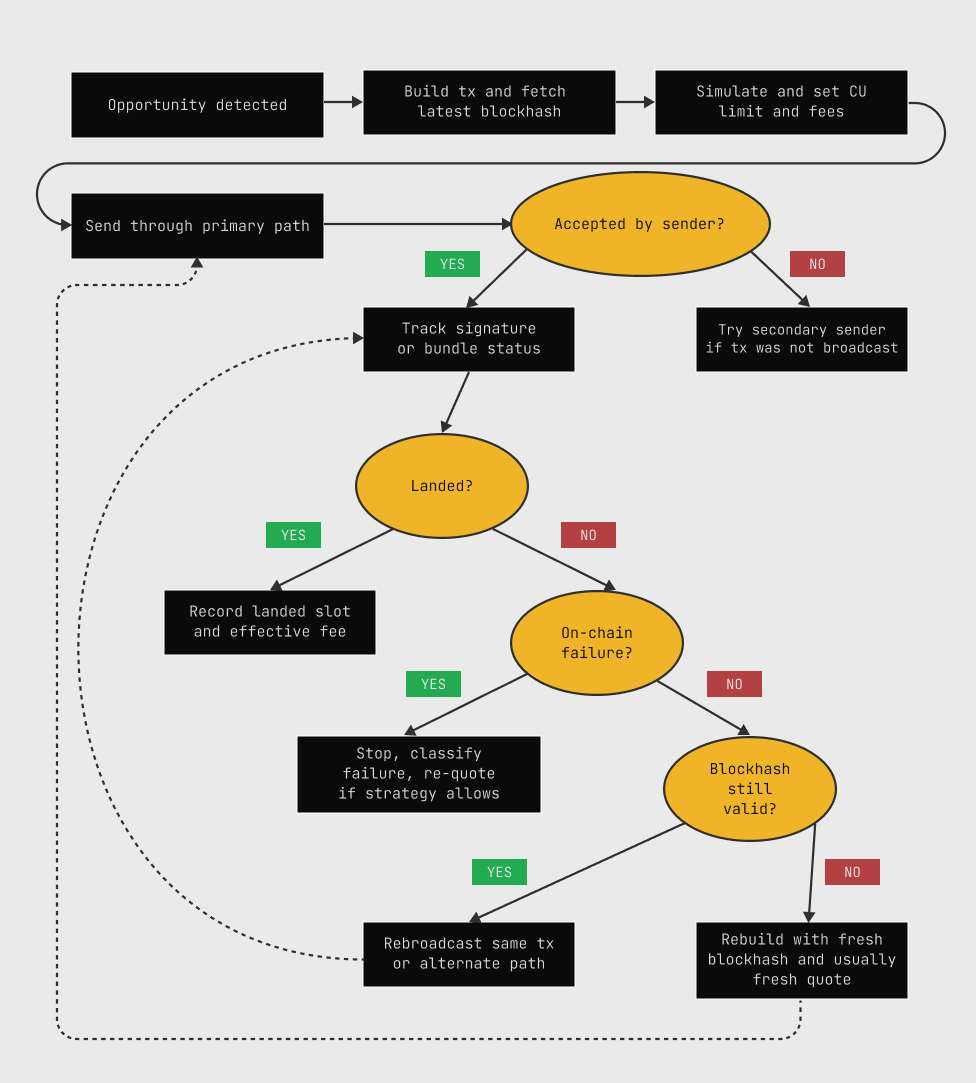
A state-aware failover loop tracks:
- Was the transaction accepted by the first sender?
- Has it been seen by the target validator or broadcast to the network?
- Is the blockhash still within its valid block height window?
- Has the transaction landed, failed on-chain, or expired?
Only with those answers can failover be executed correctly. Switching to a secondary RPC and resubmitting an already-landed transaction creates duplicate submissions that confuse accounting and may cause unexpected on-chain behavior depending on the instruction set.
Practical failover architecture for production Solana bots typically includes:
- A primary RPC provider for reads, with a secondary fallback
- A separate write path (which may be the same provider, Jito, or a managed sender)
- Health checks on all paths, running continuously rather than reactively
- WebSocket reconnect logic that can distinguish "no updates" from "stream disconnected"
- gRPC stream recovery with replay or backfill to close gaps
- Regional endpoint options for latency-sensitive strategies
The last point on WebSocket reconnects is worth pausing on. A bot that silently loses its account subscription and keeps running on stale state is worse than a bot that stops. Stream health should be a first-class metric.
Retail bot vs production trading infrastructure
The clearest way to frame the architecture gap:
| Retail Solana bot | Production Solana trading infrastructure |
|---|---|
| Telegram or SaaS interface | Custom backend and infrastructure stack |
| One endpoint or vendor-managed infrastructure | Dedicated RPC / private RPC / multi-provider routing |
| Limited visibility into transaction failures | Full transaction status tracking: landed, failed, expired |
| Static or hidden fee logic | Dynamic priority fee calibrated to recent network conditions |
| Basic alerts | Real-time data streams with indexed history for post-trade analysis |
| Manual troubleshooting | Monitoring, retries, failover, alerting |
| User-level workflow | Workload-level architecture with explicit failure classification |
A retail bot is not poorly built because the developers are lazy — it is constrained by design. SaaS and Telegram products hide infrastructure decisions to reduce complexity for end users. The cost of that abstraction is visibility: when something goes wrong, you cannot diagnose it, and you cannot fix it. That tradeoff is acceptable for casual use and starts to matter a lot when real capital is involved.
Metrics to monitor for a Solana trading bot
Production Solana bot operations should monitor the pipeline, not just final outcomes. The metrics that actually matter:
- Data freshness — how old is the data the strategy is acting on?
- Quote age — time elapsed between fetching the quote and submitting the transaction
- Stream lag — is the WebSocket or gRPC feed behind the chain tip?
- RPC latency — read and write paths tracked separately
- Transaction send latency — time from sign to accepted-by-sender
- Landed rate — percentage of sent transactions that actually confirm on-chain
- Failed rate — percentage that land but revert on-chain (fees still charged)
- Expired blockhash rate — percentage that expire before landing
- Confirmation latency — time from send to confirmed slot
- Fee paid per landed transaction — actual cost against expected cost
- Retry count — average and outlier distribution
- RPC error rate —
429,403, timeouts, tracked by provider and path - WebSocket disconnect frequency
- gRPC stream gaps and recovery time
- Jito bundle status — accepted, rejected, landed — for workloads using bundles
If the expired blockhash rate is climbing, that is usually a data freshness or fee calibration problem, or both. If the landed rate is dropping while send latency is stable, the issue is more likely in the submission path or fee policy. Those distinctions are only possible with this kind of instrumentation.
How to choose infrastructure for your Solana trading bot
The infrastructure decision is not primarily about which provider has the best landing page. It is about matching workload requirements to the right setup.
Some honest questions to work through:
- Is this a retail exploration, a prototype, or a production workload? The answer changes almost every other decision.
- How fresh does the data need to be? Real-time arbitrage and listing bots need millisecond-level freshness; rebalancing bots usually do not.
- How many transactions per minute at peak? This is where shared RPC rate limits either matter or do not.
- Do you need WebSocket or gRPC? For most backend bots, Yellowstone gRPC is increasingly the better choice where available.
- Who manages priority fees — static hardcoding, dynamic sampling from recent network data, or a managed service?
- Does the strategy benefit from Jito paths or bundles?
- What happens when the primary RPC endpoint degrades? Does the bot fail gracefully, retry with state awareness, or retry blindly?
- Are landed, failed, and expired transactions tracked separately?
- Is there a path for post-trade analysis and strategy evaluation?
- Does the team have monitoring, alerting, and a kill switch?
If most of those answers are "we haven't decided yet," a shared RPC provider with WebSocket support, a routing API like Jupiter's managed path, and basic confirmation tracking is a reasonable starting point. Grow the stack as the workload grows.
If several of those answers are "we have outgrown the current setup," dedicated RPC, gRPC streaming, and custom sender configuration are the next steps. For workloads that have moved past public or shared endpoints and need stable reads, real-time data, and reliable transaction submission, dedicated Solana RPC infrastructure is worth comparing at that stage.
Conclusion
A Solana trading bot starts as an automation layer and, in production, becomes an infrastructure workload — and those two things require meaningfully different investment. Once latency, capital, or user trust is involved, data freshness, route quality, fee calibration, transaction validity, sender choice, failover behavior, and post-trade observability tend to matter as much as the strategy itself.
Deciding what to trade is one half of the problem. Successfully landing it, classifying the result, and knowing what to do next is the other half — and over the past year working on Solana execution infrastructure, we have not seen that second half get easier as workloads scale.
